
راه اندازی کلاستر Redis
Redis یک دیتابیس NoSql است که علاوه بر استفاده به عنوان دیتا بیس با توجه به ویژگی های اون می توانیم Redis رو به عنوان Cache و Message Broker هم استفاده کنیم. در این پست بهتون یاد میدم چطور یک کلاستر Redis پیاده سازی کنید.

Redis یک دیتابیس NoSql است که علاوه بر استفاده به عنوان دیتا بیس با توجه به ویژگی های اون می توانیم Redis رو به عنوان Cache و Message Broker هم استفاده کنیم.
آیا نگه داری داده ها در RAM باعث از دست رفتنشون نمیشه ؟
خوب این سوالی هست که هر تازه کاری باید در ابتدا بپرسه! آیا از آنجایی که Redis داده ها را روی RAM نگه می داره ، بعد از خاموش و روشن شدن و یا هر اتفاق غیر قابل پیش بینی که بیافتد و RAM سیستم خالی شود داده های ما پاک می شوند؟
خیر ، Redis برای نگه داری دائمی داده ها آنها را با توجه به تنظیماتی که ما برای آن مشخص می کنیم به دیسک اصلی سیستم منتقل می کند و بعد از پاک شدن RAM دوباره می تواند آنها را منتقل کند و کار را از سر بگیرد.
کلاستر Redis
یکی از تغییرات مهم Redis این بود که از نسخه 3.0 به بعد قابلیت پشتیبانی از بحث کلاسترینگ به طور پیش فرض بهش اضافه شد. کلاستر Redis مانند تمام کلاستر ها مجموعه ای از Worker هاست که همزمان کار میکنن.
جهت مطالعه بیشتر به پست زیر در وبسایت Redis مراجعه کنید :


توپولوژی کلاستر
در ابتدا به تعداد و ترکیب Worker ها می پردازیم. چیزی که Redis پیشنهاد کرده اینطوره :
- ۳ سرور مجزا
- کانفیگ ۳ Master Node روی هر دستگاه
- کانفیگ ۳ Slave Node به ازای هر Master
کلاسترینگ Redis از یک روش توزیع شده برای مرتب سازی داده ها در حافظه استفاده میکنه به این صورت که 16384 اسلات را بین کل Node ها تقسیم میکنه و برای اینکه هر اسلات جداگانه شناسایی بشه از CRC16 استفاده کرده و Hash هرکدام مشخص میشه. در نهایت هر Node وظیفه داره تا بازه مشخصی از اسلات ها رو مدیریت کنه. برای مثال ٬ یک کلاستر با ۳ نود به اینصورت عمل میکنه :
- نود اول : شامل هش های بین 0 تا 5000
- نود دوم : شامل هش های بین 5001 تا 10000
- نود سوم : شامل هش های 10001 تا 16383
در نهایت چنین ترکیبی باعث میشه تا بدون هیچ downtime بتونیم نود های مختلف رو در سطح کلاستر اضافه یا حذف کنیم.
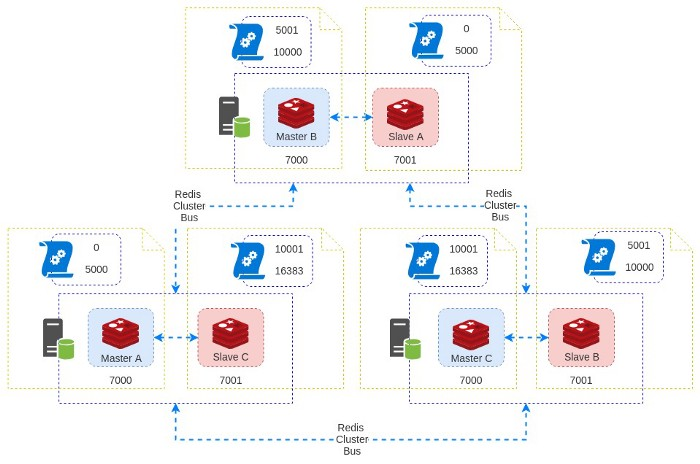
روند Fail-Over
همین توپولوژی که الان توضیح داده شد در نظر بگیرید ٬ چنین دیاگرامی خواهیم داشت :
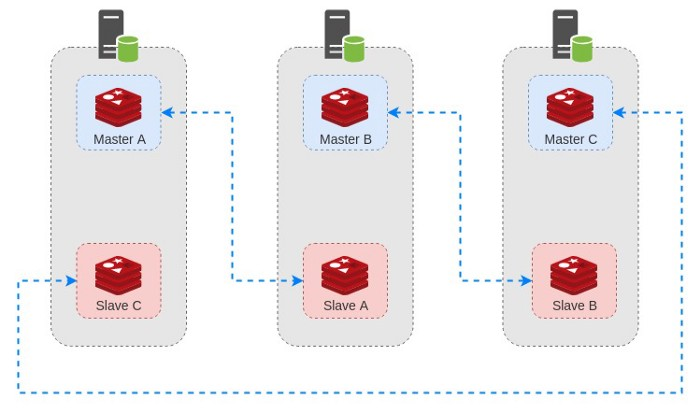
هرگاه یکی از سرور ها دارای مشکل شده و از شبکه خارج بشه ٬ کلاستر به طور خودکار یکی از Slave ها رو به Master تبدیل میکنه. فرض کنید در همین دیاگرام ٬ سرور دوم از دسترس خارج بشه :
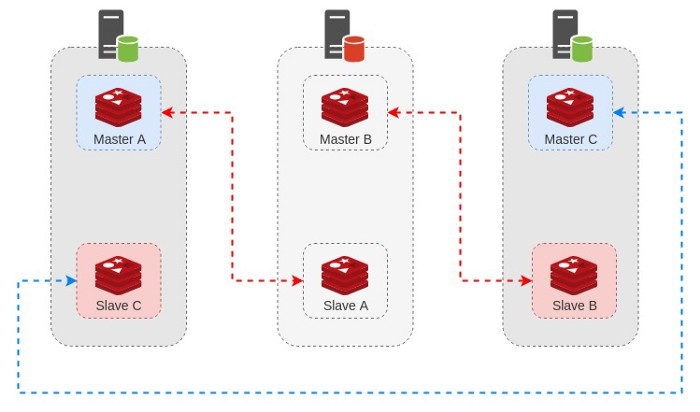
وقتی کلاستر تشخیص بده که Master B در دسترس نیست ٬ روند FailOver انجام میشه و Slave B رو به عنوان Master جدید قرار میده :
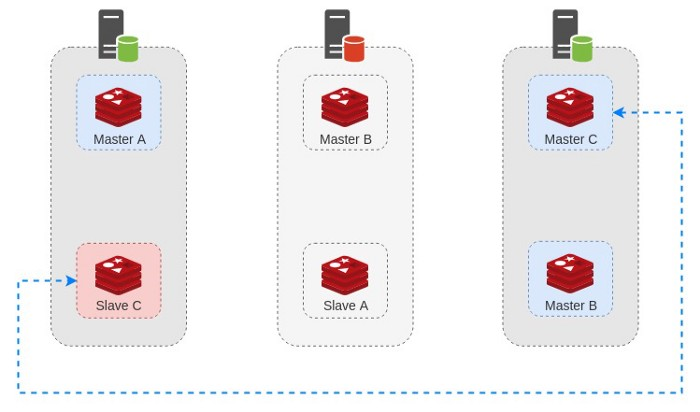
وقتی که مشکل برطرف بشه و سرور دوم مجددا به روند قبلی خودش برگرده ٬ کلاستر مجددا به روزرسانی شده و سرور به مجموعه بر میگرده :
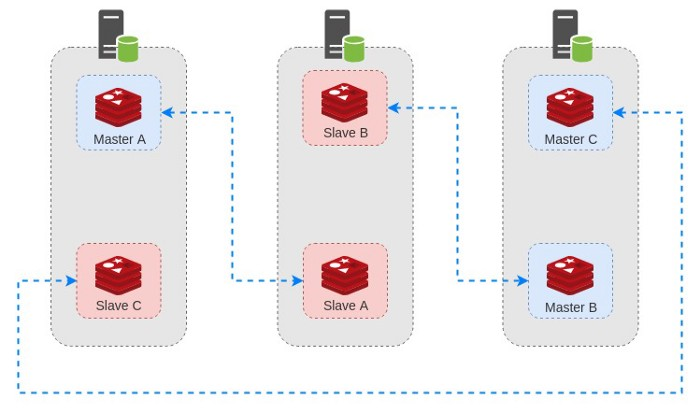
توجه کنید که در این حالت ٬ یک شرایط ویژه و خطرناک رخ میده. چرا که اگر به دیاگرام بالا دقت کنید ٬ با اینکه همه ی اجزا وجود دارن ولی دیگه سر جای خودشون نیستن. حالا ما ۲ نود Master در یک سرور داریم که اگر اون سرور ( سرور اول ) از کار بیوفته با مشکلات بیشتری مواجه میشیم.
پیاده سازی کلاستر در Kubernetes
حال که با توپولوژی و نحوه کار کلاستر Redis آشنا شدیم ٬ پیاده سازی اون رو بررسی می کنیم. راه های زیادی برای این کار وجود داره ( فعلا برای آزمایش و محیط توسعه ) برای مثال میتونیم 6 ماشین مجازی بسازیم یا ۶ کانتینر داکر یا اگر زیرساختش موجوده و میخواید خیلی دل به کار بدید روی 6 سرور فیزیکی مجزا :)))
از نسخه 3 به بعد که قابلیت کلاسترینگ به Redis اضافه شد ٬ برای مباحث ایجاد یا ویرایش و تغییر اندازه ی کلاستر کتابخانه ای هم به نام redis-trib منتشر شد. حالا پس از گذشت چند نسخه ٬ دیگه نیازی به این برنامه نیست و تمام تنظیمات مربوط به کلاستر از طریق CLI پیش فرض در دسترس شماست.
اگه دنبال این هستید که بدونید معنی
tribچیه و اصلا چرا اسم این پروژهredis-tribانتخاب شده ٬ باید بگم که هیچ دلیل خاصی وجود نداره :))
استقرار
به علت وجود الگوی stateless در ساختار کوبرنتیز ٬ کمی سخت میشه که کلاستر Redis با توپولوژی ذکر شده طراحی و مدیریت کرد چون هر Instance از این کلاستر شامل فایلی میشه که اطلاعات مربوط به کلاستر و باقی نود ها رو هم تو خودش ذخیره میکنه و در نتیجه باعث میشه تا کل Instance ها از وضعیت هم باخبر بشن.
این یعنی در حین طراحی کلاستر باید حالت ویژه ای رو در نظر بگیریم تا این امر به درستی انجام بشه و راه حلش هم استفاده ترکیبی از StatefulSets و PersistentVolumes است.
در ابتدا به بحث deployment می پردازیم. فایلی با محتوای زیر آماده کنید :
---
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-cluster
data:
update.sh: |
#!/bin/sh
REDIS_NODES="/data/nodes.conf"
sed -i -e "/myself/ s/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/${POD_IP}/" ${REDIS_NODES}
exec "$@"
redis.conf: |+
cluster-enabled yes
cluster-require-full-coverage no
cluster-node-timeout 15000
cluster-config-file /data/nodes.conf
cluster-migration-barrier 1
appendonly yes
protected-mode no
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
spec:
serviceName: redis-cluster
replicas: 6
selector:
matchLabels:
app: redis-cluster
template:
metadata:
labels:
app: redis-cluster
spec:
containers:
- name: redis
image: redis:6.0.6-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: client
- containerPort: 16379
name: gossip
command: ["/conf/update.sh", "redis-server", "/conf/redis.conf"]
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: conf
mountPath: /conf
readOnly: false
- name: data
mountPath: /data
readOnly: false
volumes:
- name: conf
configMap:
name: redis-cluster
defaultMode: 0755
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Mi
همانطور که قبلا توضیح داده شد ٬ برای این کلاستر نیاز به 6 نود داریم که ۳ تای آن ها به صورت Master و ۳ تای دیگه به عنوان Slave عمل میکنن.
وقتی یک StatefullSet ایجاد می کنیم ٬ نتیجه گروهی از Instance های مجزای Redis میشه که با توجه به تنظیماتی که جلوتر توضیح میدم ٬ هرکدوم از این نود ها در حالت کلاستر یا Cluster Mode اجرا میشن.
علاوه بر این ٬ هرکدوم از اون ها درخواست یک Volume مجزا برای ذخیره سازی داده هاشون دارن که این کار از طریق PersistentVolumeClaim انجام میشه. تمامی روند تخصیص volume همانطور که تو فایل بالا مشاهده می کنید در بخش volumeClaimTemplates به صورت خودکار اتفاق میوفته.
جهت کار با کلاستر به دو فایل config نیاز داریم که این کار از طریق ConfigMap انجام میشه.
- فایل اول به نام
update.sh: یک اسکریپت ساده است که در هر مرحله آدرس آی پی Pod فعلی را دریافت کرده و با توجه به اون فایل تنظیمات کلاستر که در مسیرdata/nodes.conf/وجود داره رو به روزرسانی میکنه. - فایل دوم به نام
redis.conf: فایل تنظیمات پیشفرض Redis بوده که با توجه به نوع پیاده سازی و شرایط میتونید تغییرش بدید. توجه داشته باشید که تنظیمات مربوط به فعالسازی کلاستر و فایل مربوط به اون در این بخش قرار داره.
در نهایت این فایل رو با استفاده از دستور زیر اعمال کنید :
kubectl create -f statefulset.yml
وقتی تمام Pod ها آماده شد ٬ به مرحله بعد میریم تا کلاستر رو تشکیل بدیم
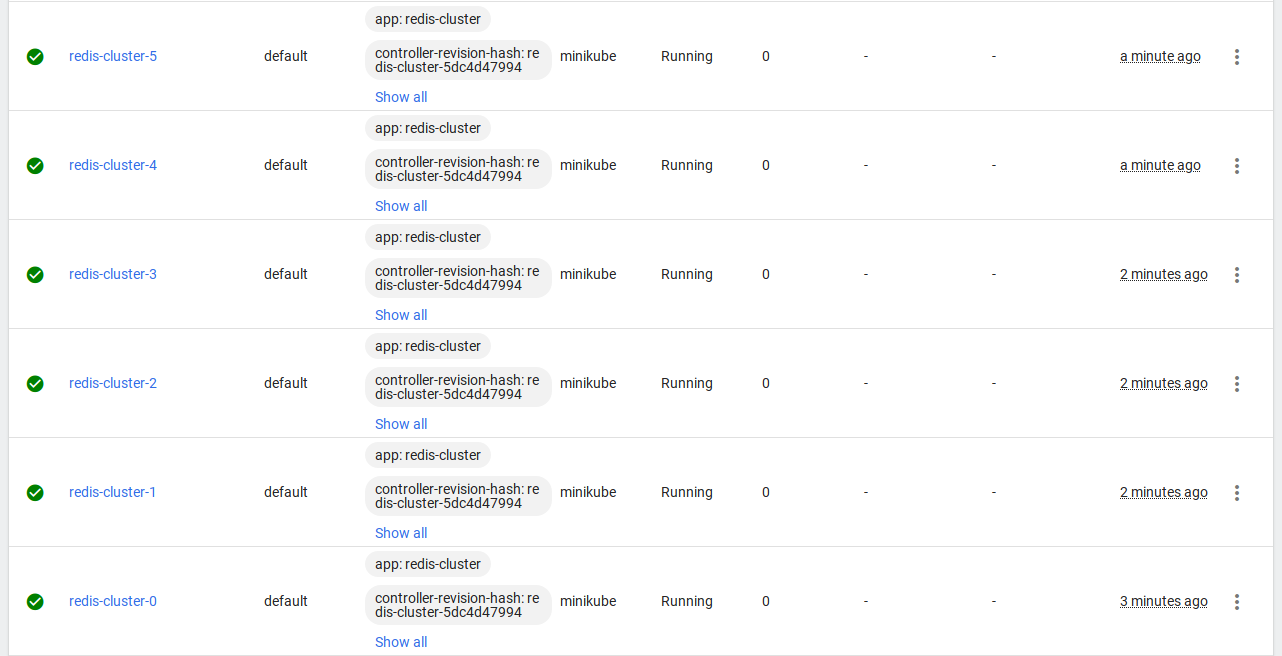
همچنین مشاهده میکنید که با استفاده از volumeClaimTemplates به طور خودکار 6 فضای ذخیره سازی هم برای Pod ها اختصاص داده شده :
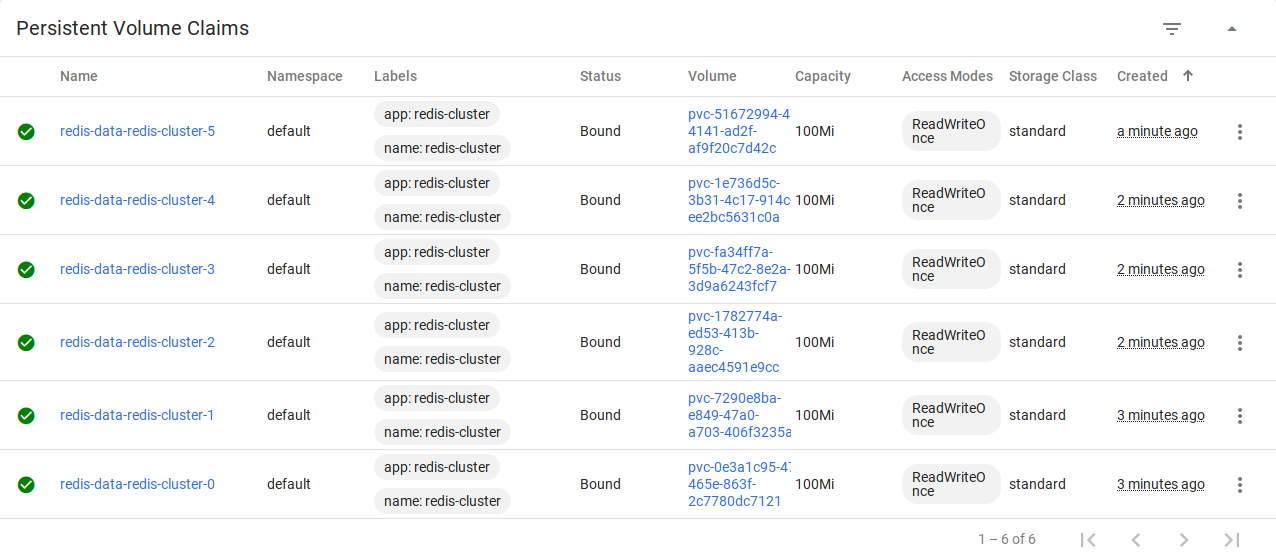
حالا نیاز داریم تا سرویسی برای دسترسی به کلاستر تعریف کنیم. فایلی با نام service.yml و محتوای زیر آماده کنید :
---
apiVersion: v1
kind: Service
metadata:
name: redis-cluster
spec:
type: ClusterIP
ports:
- port: 6379
targetPort: 6379
name: client
- port: 16379
targetPort: 16379
name: gossip
selector:
app: redis-clusterاین فایل هم با دستور زیر اعمال کنید :
kubectl create -f service.ymlساخت کلاستر نهایی
تا اینجای کار ما 6 نود مجزا داریم که به درستی کانفیگ شده و کار می کنن. هرکدوم از اونها هم Volume اختصاصی خودشون رو دارن تا اطلاعات مربوط به کلاستر رو برای پیاده سازی توپولوژی ذکر شده ٬ ذخیره کنن.
حالا باید کلاستر اصلی رو تنظیم کنیم. اینجا از دستور redis-cli --cluster استفاده می کنیم. روش کار به این صورته :
redis-cli --cluster create --cluster-replicas <Replica count> <Node list>
از اونجایی که قراره 3 Master با 3 Slave مجزا داشته باشیم مقدار replicas برابر با 1 خواهد بود. جهت اطلاعات بیشتر در مورد کلاستر Redis به این آموزش مراجعه کنید :
ابتدا باید لیست نود ها رو به دست بیاریم. برای این کار از چنین دستوری استفاده می کنیم :
kubectl get pods -l app=redis-cluster -o jsonpath='{range.items[*]}{.status.podIP}:6379 '
خروجی این دستور لیست ip:port شامل کل نود های ماست. از اونجایی که قبلا از label مناسب برای Pod هامون استفاده کردیم ٬ شناسایی اونها ساده تر میشه.
نکته مهم : در انتهای رشته یک کارکتر خالی وجود داره. برای جداسازی لیست نود ها ازش استفاده میشه. فکر نکنید اشتباهی رخ داده و اون رو پاک کنید :))
حالا کافیه دستور redis-cli --cluster create رو اجرا کنیم :
kubectl exec -it redis-cluster-0 -- redis-cli --cluster create --cluster-replicas 1 <<node-list>>
در قسمت <<node-list>> باید لیست نود هایی که از دستور قبل به دست آورده اید را قرار دهید. در صورت لازم این دو دستور رو میتونید ادغام کنید :
kubectl exec -it redis-cluster-0 -- redis-cli --cluster create --cluster-replicas 1 $(kubectl get pods -l app=redis-cluster -o jsonpath='{range.items[*]}{.status.podIP}:6379 ')
خروجی دستور چنین چیزی است :
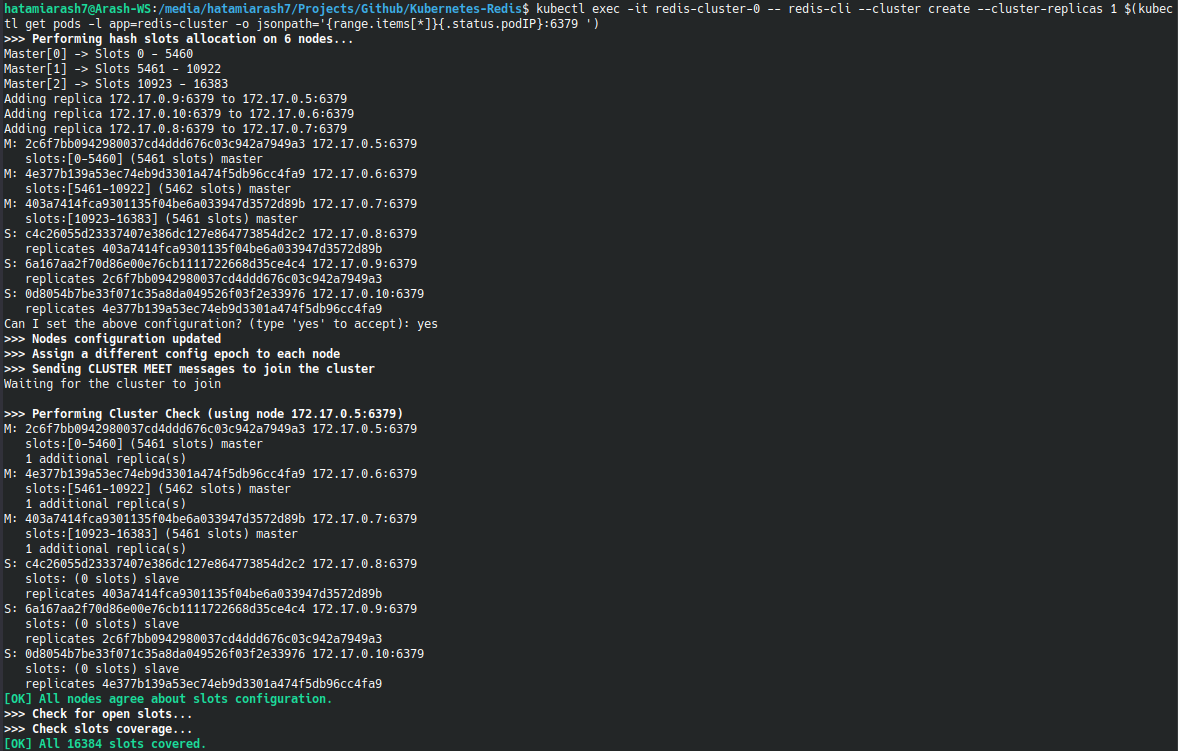
همینطور که مشاهده می کنید بحث تخصیص اسلات ها هم برای شما نمایش داده شده.
حالا کلاستر شما با همان توپولوژی مطلوب ساخته شده و میتونید ازش استفاده کنید. جهت اطلاع از وضعیت نود ها می تونید از چنین دستوری استفاده کنید :
kubectl describe nodes
کلیه کد های مربوطه در این ریپازیتوری موجوده :
 hatamiarash7
hatamiarash7
چند نکته مهم
- این توضیحات صرفا جهت آشنایی با کلاسترینگ و راه اندازی در محیط توسعه بود ٬ برای شرایط Production مسلما به تغییرات و تنظیمات مناسبی نیاز خواهید داشت
- جهت انجام چنین کاری در کلاستر کوبرنتیز Multi-Node باید از مدل ذخیره سازی متفاوتی برای StatefulSet استفاده کنید. در چنین شرایطی مسلما hostpath جوابگو نیست