
مانیتورینگ 200 هزار درخواست DNS در ثانیه
یکی از بهترین راه ها برای شناسایی و جلوگیری از مشکلات احتمالی در حملات مربوط به DNS ٬ مانیتور کردن این داده هاست. تو این پست مشکلات ٬ راهکار های موجود و راه حل نهایی رو شرح میدم.

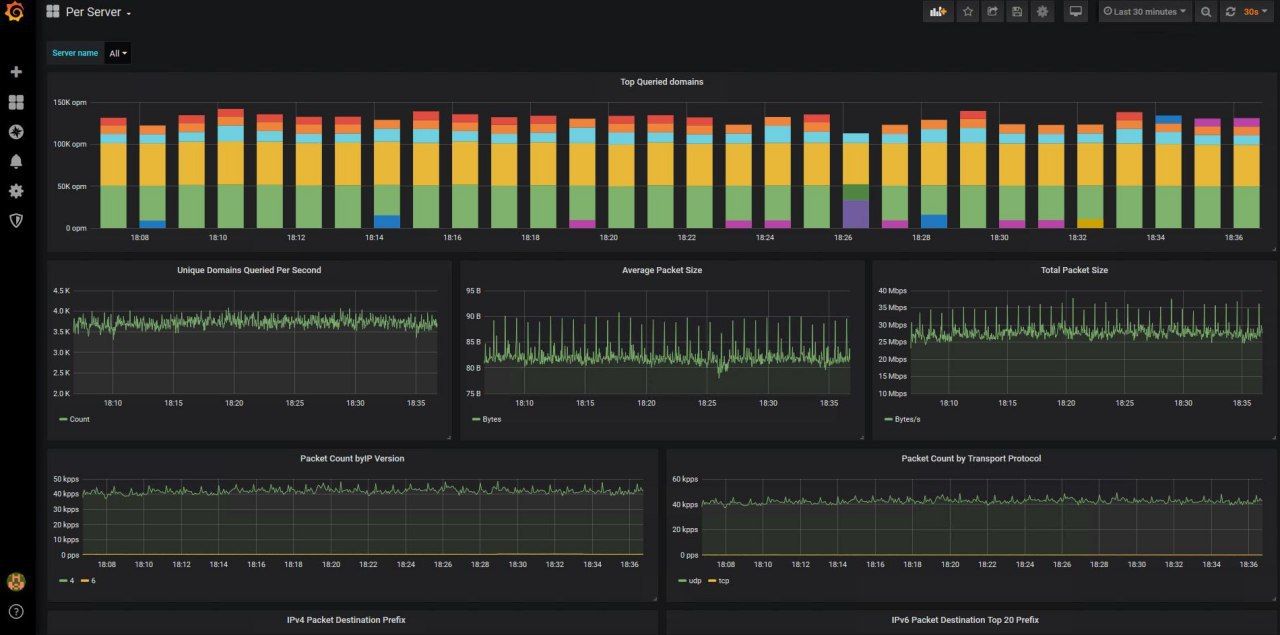
چرا باید درخواست های DNS را مانیتور کرد ؟
رویه های عادی امنیتی مانند استقرار فایروال ٬ سنسور های IDS ٫ ابزار های NSM و غیره همیشه وجود داشته اند. امنیت اطلاعات حالا بیشتر از قبل شبکه محور شده و در کنار اون ٫ هکر ها نیز با این روند سازگار شده و حملات خرابکارانه ی گسترده ای تو این حوزه اتفاق می افته.
امروزه بسیار مشاهده میشه که بدافزار ها یا هکر ها از DGAs یا حملات DNS به صورت ارسال سریع داده و راه های مختلف برای مسدود/شناسایی آدرس های آی پی مختلف استفاده میکنن. کاملا واضح و روشنه که نظارت بر فعالیت های DNS در داخل شبکه و تلاش برای یافتن ناهنجاری های مرتبط با اون ٫ در این زمینه کمک های زیادی به افزایش امنیت می کنه.
بررسی گزینه های موجود
شاید همین الان چنین سوالی تو ذهنتون شکل بگیره : " چرا تمام داده ها رو به Elasticsearch یا Splunk منتقل نکنیم و روی داده هامون Query اجرا کنیم ؟ "
خب همین اول کار لازمه که گزینه های تجاری مثل Splunk رو به کلی فراموش کنیم. تو این مبحث ما در مورد حدودا ۱ ترابایت داده در روز صحبت می کنیم که حجم قابل توجهی از رکورد هاست. Splunk یک گواهینامه گران قیمت ۱۸۰۰ دلار به ازای هر گیگابایت داره. البته با افزایش حجم این مبلغ کم میشه. فرض کنیم که یک تخفیف ۹۰ درصدی برای ارسال ۳ ترابایت داده در روز هم داشته باشیم
$1800/GB * 1024GB * (100 - 90) / 100 = $184,320
با این حجم از داده تقریبا سالی ۱۸۵ هزار دلار برای خودمون هزینه درست کردیم !!! خب مسلما استفاده از چنین مواردی منطقی نیست.
گزینه بعدی میشه ES. بهترین راه برای ذخیره و بازیابی داده ها با فرمت JSON که قالب مشخصی هم ندارن. اینجا سناریوی های مختلفی برای بحث ذخیره سازی وجود داره. مثلا :
- استفاده از PacketBeat برای ارسال دیتا به ES
- استفاده از PacketBeat برای ارسال دیتا به Logstash و ES
- استفاده از PassiveDNS برای ذخیره سازی داده های خام DNS به صورت فایل و ارسال داده ها با استفاده از Filebeat یا Logstash
این راهکار ها و موارد مشابه دیگه ٬ یه مشکل اساسی دارن. این حجم عظیم داده برای ES به احتمال زیاد باعث ایجاد مشکلات اساسی توی اجرا و نمایش داده ها شد. این مورد روی سخت افزار این چنینی تست شده :
- OS: Red Hat Enterprise Linux 7.7 Maipo
- Kernel: Linux 3.10
- Disk: 44TB HDD
- CPU: Intel Xeon Gold 5122 @ 16x 3.7GHz
- RAM: 192GB
چنین نتیجه ای فقط دو دلیل میتونه داشته باشه ٬ یا ES برای ذخیره داده های زیاد ( تقریبا ۱۵۰ هزار در دقیقه ) ساخته نشده ٬ یا اینکه تنظیمات و کانفیگ های خاصی باید برای این مورد انجام بشه. در نهایت ES هم گزینه رد شده ای حساب شد.
حالا راهکار مناسب چیه ؟
استفاده از ClickHouse

شاید خیلی از شماها اسم ClickHouse به گوشتون خورده باشه. از این DBMS ستون-محور برای ذخیره و آنالیز حجم زیادی از داده ها در لحظه استفاده میشه. با توجه به ساختاری که داره سرعت خیلی بالایی در نوشتن و در عوض سرعت کمی برای خواندن اطلاعات داره که خب با توجه به موضوع کاری ما خیلی مناسبه. ما در لحظه حجم عظیمی از داده های DNS رو ذخیره میکنیم ولی با همون سرعت نیاز با بازیابی و آنالیزشون نداریم. تو پروژه ی ما در بدترین شرایط نسبت نوشتن به خواندن ۱ میلیون به ۱ میشه. یعنی به ازای هر ۱ میلیون داده که ذخیره میکنیم یک دستور Select اجرا می کنیم تا داده های قبلی رو آنالیز کنیم یا توی داشبورد خودمون نشون بدیم.
شاید براتون جالب باشه که بدونید همین الان Cloudflare هم از چنین روشی برای آنالیز داده های DNS خودش استفاده میکنه. برای اطلاعات بیشتر این پست از وبلاگشون رو بخونید. توضیح دادن که با استفاده از ClickHouse حجم عظیم ۱ میلیون داده بر ثانیه رو آنالیز میکنن.
مشکلات جمع آوری / ارسال داده ها
در حال حاضر ابزار های زیادی برای بررسی داده های شبکه و Interface ها وجود داره. مشهور ترین نمونه ی اون PassiveDNS که وقتی کاربرد داره که بخواید حجم های کمتر از سناریوی ما رو پردازش کنید. در ضمن برای چنین پروژه ای نمیشه منابع سخت افزاری زیادی رو اشغال کرد. برای مثال فقط مجازیم که از یک هسته پردازنده استفاده کنیم و در صورت تکمیل ظرفیت ٬ احتمالا بخشی از ترافیک رو از دست میدیم.
گزینه جالب دیگه ای گه وجود داره gopassivedns که در واقع همان پروژه قبلی است ولی از زبان GO برای توسعه اون استفاده شده. ولی خب این پروژه هم مشکلات خودش رو داره از جمله :
- هنوز ۱۰۰ درصد کامل نیست
- به صورت مستقیم به دیتابیس متصل نمیشه و داده ها رو فقط ذخیره میکنه. این یعنی نیاز به ظرفیت زیادی از هارد دیسک
- از بسته های Dot1Q پشتیبانی نمیکنه
پس این مورد هم کنسل !!
در این بین کتابخانه dnszeppelin هم موجوده که یه مشکل اساسی رو حل کرده ! اونم اتصال مستقیمش به ClickHouse که برای سناریو ما خیلی عالیه. ولی همچنان مشکل عدم پشتیبانی از Dot1Q رو داره.
راه حل نهایی
پروژه خیلی خوبی برای رفع تمام این ایرادات توسط علی مسجل نوشته شده و درواقع ترکیب موارد بالا است که ویژگی های زیر رو داره :
- اتصال مستقیم به ClickHouse
- اجرا به صورت یک فایل باینری ساده
- پشتیبانی از Dot1Q
- بسیار سبک و سریع
این پروژه که DNSMonster نام داره دقیقا همون کاری رو انجام میده که مد نظر ماست. روند پروژه به این صورت میشه
- اجرای dnsmonster در شبکه داخلی و بررسی بسته ها
- اجرای یک کانتینر از ClickHouse برای ذخیره سازی و بازیابی داده ها
- یک cronjob برای حذف داده های قدیمی
- استفاده از Grafana برای نمایش داده ها
با توجه به اینکه داده های خام در اختیار دارید میتونید خودتون هم داشبورد مدنظرتون رو با استفاده از فریمورک های مختلف از اول پیاده سازی کنید ولی خب Grafana هم از بهترین نمونه های موجوده چرا که وقتی صحبت از مانیتورینگ به میون میاد ٬ احتمالا داده های دیگه رو هم مانیتور میکنید و همین الان Grafana روی سیستمتون نصب هست و نیازی به اضافه کردن داشبورد جدیدی ندارید.
روش نصب
این پروژه به صورت متن باز تحت گواهینامه ی MIT منتشر شده که از این لینک میتونید اون رو Clone کنید.
اسکریپت Bash ساده ای هم برای نصب و اجرا وجود داره که میتونید ازش استفاده کنید :
git clone https://gitlab.com/mosajjal/dnsmonster.git && cd dnsmonster
chmod +x autobuild.sh
./autobuild.sh
این اسکریپت تمام نیازمندی ها رو به صورت کانتینر های داکر اجرا میکنه و دیتابیس رو هم تنظیم میکنه. علاوه بر این داشبورد Grafana هم برای ما میسازه و نیاز نیست هیچ کار دیگه ای انجام بدید.
برای ارسال درخواست های آزمایشی DNS جهت مشاهده داده ها از این اسکریپت استفاده کنید :
 hatamiarash7
hatamiarash7
هیچ چیز کامل نیست
با اینکه این پروژه یکی از بهترین نمونه هایی که تا حالا دیدم ولی بازم کامل نیست و مشکل بزرگی داره.
مشکل اینجاست که dnsmonster مانند wireshark عمل میکنه و باید یه Interface خاص Sniff بشه. پس مسلما نیاز داریم تا کانتینر ما به شبکه Host دسترسی داشته باشه که خب با استفاده از NET_ADMIN این گزینه حل میشه ولی علاوه بر اون باید برای عملیات Sniffing یک Interface شبکه هم به پروژه معرفی بشه. اینجاست که تو سیستم عامل ویندوز به مشکل بر میخوریم !!!
تو سیستم عامل های لینوکس یا مک اینترفیس های رایج همیشگی مثل eth0 وجود داره و ازش برای این منظور استفاده می کنیم. ولی توی ویندوز بحث فرق میکنه. اینترفیس های ما هیچ اسم مشخصی ندارن که با استفاده از اون شناسایی بشن. مدل جایگزین GUID اون هاست ولی خب متاسفانه استفاده از GUID برای این پروژه جواب نمیده. برای این منظور Issue ثبت کردم و در حال حل مشکل هستیم.
در نهایت اگر سوالی در مورد اجرا و تنظیم dnsmonster داشتید ٬ در تماس باشید.